
Before getting into the technicalities, we hope you understand the solutions provided by Amazon. Whether shopping for a home or work, most people seek a convenient and affordable method that gives value for their money.
Amazon business, being the top ecommerce platform, has never stopped bringing new opportunities for buyers and sellers. But from where does Amazon ASIN come into action? A simple code that provides unique identification to every product on a platform.
Buyers looking to sell their products on Amazon have the freedom to follow specific procedures and standards. One includes assigning the ASIN (Amazon Standard Identification Number) code to your products before you begin selling them.
In this content piece, we will guide you through the importance of Amazon ASIN code, extracting Amazon ASIN data, the benefits of Amazon ASIN data, use cases, challenges, and best practices for scraping Amazon ASIN data. This will help you channel the right opportunities to scale your ecommerce business, whether as a buyer, seller, or reseller.
What Is The Amazon ASIN Code?
Amazon's ASIN code is a combination of 10 alphanumeric numbers that identify Amazon products. It will be assigned to every product added to Amazon, but it excludes books with ISBN (International Standard Book Number) instead of ASIN.
It is essential to identify the ASIN code for your products before you start selling or making changes on Amazon. The aim of assigning this code is to monitor and handle the inventory while delivering a smooth customer experience.
Amazon ASIN code scraping involves crawling through target product pages or URLs, gathering unique product ASIN codes, and storing them in a structured format. This method allows you to easily find your competitors' products, deals, and strategies. Getting extracted data in the desired format also saves time and effort while avoiding human errors when analyzing the latest trends.
How Do You Find Amazon ASIN Manually?
There are some simple methods for finding an ASIN code when you have a limited or small number of products for which you want to find an ASIN code. These methods are ideal for people who require minimal data:
Amazon ASIN Lookup Tools
There are multiple free and paid tools to check the ASIN of the products. The official Amazon ASIN Lookup Tool provides you with all the information that leads to the success of products. You can quickly generate reports to improve your sales by understanding the following:
- Revenue Estimates
- FBA costs and profit margin
- High search volume keywords
- Suggested and trending keywords
- PPC costs
- Buybox price for new and used products
- List of similar products
Product URL
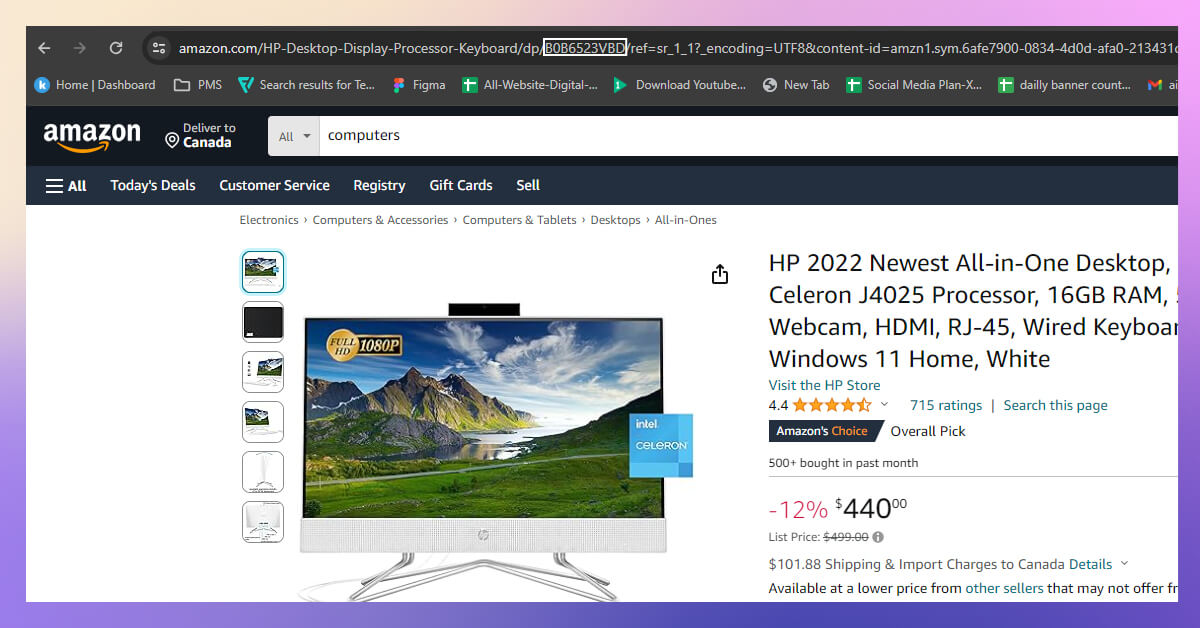
The fastest method of locating an ASIN for a product is to look in your browser's URL bar. Redirect to your desired product and look into the URL. You will find the ten-digit alphanumeric code. It will be located after the product name and "dp."
Here is an example of finding the Amazon ASIN code for your product from the URL:
Product Information Section
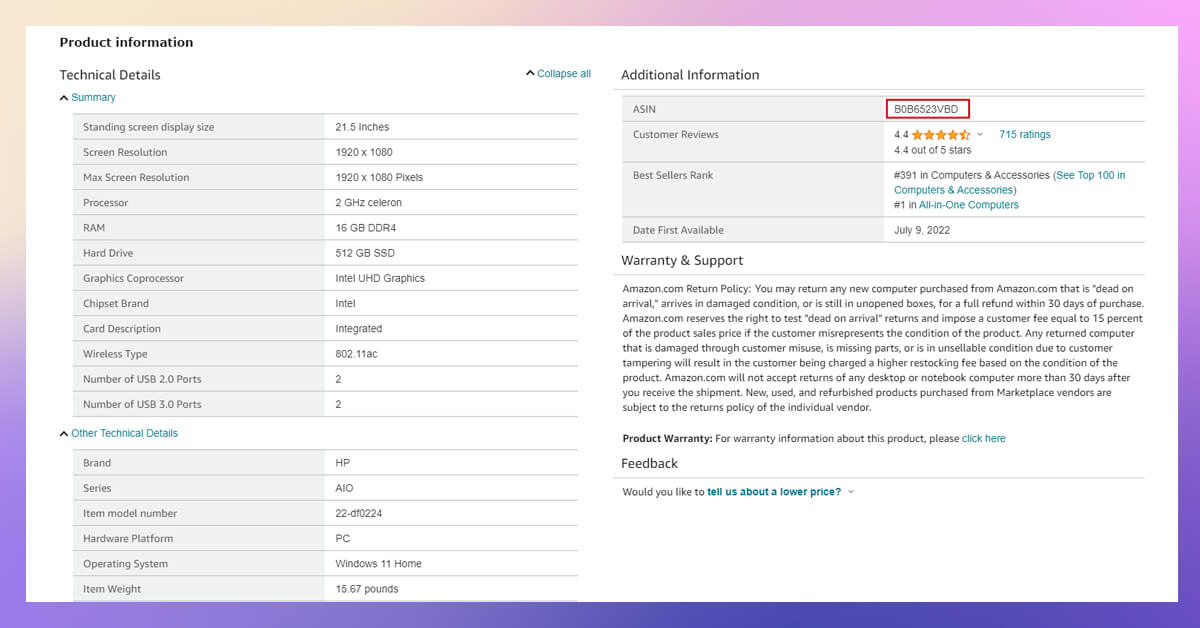
Every product page has a different section that provides detailed product information. Here is an example of finding the Amazon ASIN code from the product information:
What is Amazon ASIN API?
The API (Application Programming Interface) is a messenger between two software applications. It helps to communicate and exchange data in an organized format. Multiple third-party Amazon ASIN APIs help access publicly available product information, such as ASIN titles, descriptions, reviews, and prices.
Once you have extracted the ASIN, it can help you unlock opportunities to scale your business with the correct product information. In-depth market research can also help you track trends and popular products and analyze pricing strategies.
How to Extract Amazon ASIN data?
The fastest method of scraping Amazon ASIN data is through a reliable scraper. Let us look at the process of scraping ASIN data using the Scrapy tool:
You must install third-party software and packages before installing scrapy:
- Python: The tool is created in Python, so install this first.
- pip: A tool to manage Python packages that handle the package repository and Python libraries installation.
- lxml: If you are planning to scrape HTML data, then this optional package must be installed.
Now install Scrapy by running:
pip install scrapy
Enter the directory where you want to save the code. Then run:
scrapy startproject test_project
It creates a directory with abc name in the same place with the below contents:
test_project/
scrapy.cfg
test_project/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
Scrapy has a project structure with Object Oriented programming style that will define items and spiders for complete applications. This includes:
- scrapy.cfg: This configuration file contains the project's setting and deployment module.
- test_project: This directory with multiple files is used for running and scraping the information from the website URLs.
- item.py: Containers filled with the extracted data provide additional security against undeclared fields.
- pipelines.py: Once the spider scrapes data, it is shared in the item pipeline. Then processes it through various components. Here, items are dropped by raising the DropItem exception if required.
- settings.py: This enables customized behavior of scrapy components, which can be core, spiders, extensions, and pipelines. This also provides key-value mappings a global namespace.
- spiders: This directory contains all the spiders as Python classes.
Start by building a scrapy project using this command:
scrapy startproject amazon
Now start with items.py first:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class AmazonItem(scrapy.Item):
# define the fields for your item here like:
product_name = scrapy.Field()
product_sale_price = scrapy.Field()
product_category = scrapy.Field()
product_original_price = scrapy.Field()
product_availability = scrapy.Field()
Use the default utility known as genspider to build Spiders in the framework:
scrapy genspider AmazonProductSpider
Once you have created the AmazonProductSpider, it is time to list names, URLs, and domains to scrape the information. Here is the code:
# -*- coding: utf-8 -*-
import scrapy
from amazon.items import AmazonItem
class AmazonProductSpider(scrapy.Spider):
name = "AmazonDeals"
allowed_domains = ["amazon.com"]
#Use working product URL below
start_urls = [
"http://www.amazon.com/dp/B0046UR4F4", "http://www.amazon.com/dp/B00JGTVU5A",
"http://www.amazon.com/dp/B00O9A48N2", "http://www.amazon.com/dp/B00UZKG8QU"
]
def parse(self, response):
items = AmazonItem()
title = response.xpath('//h1[@id="title"]/span/text()').extract()
sale_price = response.xpath('//span[contains(@id,"ourprice") or contains(@id,"saleprice")]/text()').extract()
asin_code = response.url.split(‘dp’)[1]
category = response.xpath('//a[@class="a-link-normal a-color-tertiary"]/text()').extract()
availability = response.xpath('//div[@id="availability"]//text()').extract()
items['product_name'] = ''.join(title).strip()
items['product_sale_price'] = ''.join(sale_price).strip()
items['product_category'] = ','.join(map(lambda x: x.strip(), category)).strip()
items['product_availability'] = ''.join(availability).strip()
items[‘asin’] = asin_code
yield items
In the parse method, define an item object and update it with the required information using the response object's XPath utility. After Scrapy calls item pipelines for processing, the classes store the data in a database or file as required.
# -*- coding: utf-8 -*- # Define your item pipelines here # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class AmazonPipeline(object): def process_item(self, item, spider): return item
Before using pipeline classes, one has to enable it through the settings.py module:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline-html
ITEM_PIPELINES = {
'amazon,pipelines. AmazonPipeline': 300,
}
Now all the setup is completed, we need to run Scrapy and call Spider to send requests and gather response objects:
scrapy crawl AmazonDeals
In case we want to save item fields in a file, we can list the filename while calling the spider, which will automatically add the return objects from pipeline classes to the file:
scrapy crawl AmazonDeals -o items.json
As we will be returning item objects into the items.json file. Here is the output:
[
{"product_category": "Electronics,Computers & Accessories,Data Storage,External Hard Drives", "product_sale_price": "$949.95", "product_name": "G-Technology G-SPEED eS PRO High-Performance Fail-Safe RAID Solution for HD/2K Production 8TB (0G01873)", "product_availability": "Only 1 left in stock", "asin": "B0046UR4F4." },
{"product_category": "Electronics,Computers & Accessories,Data Storage,USB Flash Drives", "product_sale_price": "", "product_name": "G-Technology G-RAID with Removable Drives High-Performance Storage System 4TB (Gen7) (0G03240)", "product_availability": "Available from these sellers", "asin": "B00JGTVU5A." },
{"product_category": "Electronics,Computers & Accessories,Data Storage,USB Flash Drives", "product_sale_price": "$549.95", "product_name": "G-Technology G-RAID USB Removable Dual Drive Storage System 8TB (0G04069)", "product_availability": "Only 1 left in stock", "asin": "B00O9A48N2." },
{"product_category": "Electronics,Computers & Accessories,Data Storage,External Hard Drives", "product_sale_price": "$89.95", "product_name": "G-Technology G-DRIVE ev USB 3.0 Hard Drive 500GB (0G02727)", "product_availability": "Only 1 left in stock", "asin": "B00UZKG8QU."}
]
Now, you can store the information in your desired format, making it easier to access and analyze.
Why Scrape Amazon ASIN Data?
With millions of valuable ecommerce products, the platform serves as an inventory to understand the market. There are two perspectives of scraping Amazon ASIN data:
Sellers
It will help sellers, and Amazon monitor inventory and index catalog pages. The Amazon ASIN code lets sellers search through multiple categories, track inventory, and accurately index catalogs.
Buyers
An Amazon ASIN code makes it effortless to search products through multiple categories. For example, if you need to purchase a specific laptop model, it is easier to identify products faster.
With Amazon product data scraping, you can easily gather information in bulk, like product title, pricing, description, ASIN code, ratings, shipping info, and other publicly available data. You can be a buyer, seller, reseller, or startup business looking to gather market demands.
What Are The Challenges In Amazon ASIN Data Scraping?
Knowing the legal methods to avoid penalties is essential before investing in scraping Amazon ASIN data. Amazon is highly invested in protecting its information to prevent misuse or illegal practices.
Here are the challenges you might face while scraping ASIN code from Amazon:
IP blocking
The platform has multiple methods for detecting a bot by monitoring browsing behavior. There are chances that the URLs change by a query parameter at regular intervals, showcasing that a program is exploring the pages. So, there might be IP bans and Captchas to block the bots, which is necessary to secure the information.
Different Page Structure
When you scrape through Amazon, you may encounter unknown response errors and exceptions. Most scrapers follow a specific page structure, extract HTML information, and gather relevant information. So, when the page structure changes, there are higher chances of failing if no measures are taken to handle exceptions.
Minimal Features And Solutions
There are many tools to scrape Amazon ASIN data, but some might not have the efficiency and speed required for the complete process. The crawler might crash or bring minimal output when you want to extract bulk information due to limitations.
Best Practices In Data Extraction Of Amazon ASIN
When scraping Amazon data, it is essential to understand does Amazon blocks web scraping? Yes, if you do not follow the proper measures, rules, and standards to get quality and accurate results. Here are some things you must consider:
- Bulk Scraping: When you aim to extract large amounts of data, sending separate requests for every page is essential. Also, sending too many requests in smaller intervals can overload the servers and affect the website's performance. So, follow the proper methods of scraping data from Amazon.
- Use Proxies: It is easier to use proxies that mask your IP address and bypass IP blocking. They mediate between your scraper and Amazon to send requests from different IP addresses.
- Implement Delays: Delays and randomization are implemented when you need to scrape bulk data. This lets your tools mimic human browsing behavior and avoid detection during scraping activities.
- JavaScript Usage: Most ecommerce websites rely on JavaScript rendering to handle dynamic content. This lets you crawl all the segments of the webpage easily.
Use-Cases Of Amazon ASIN Product Data Scraping
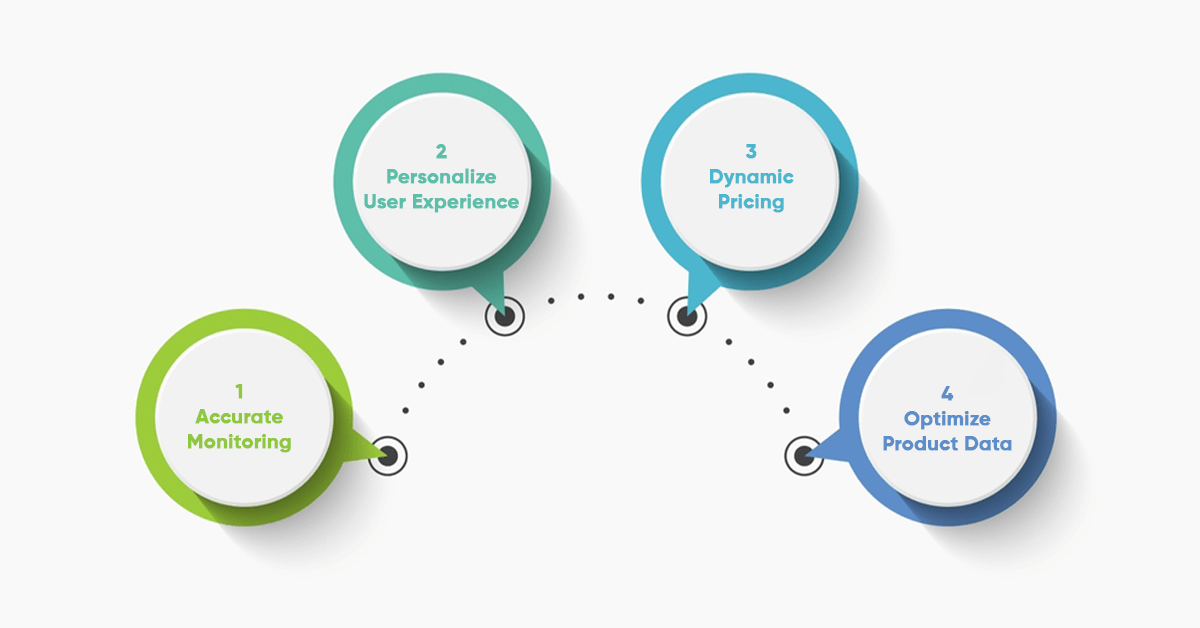
Once you have extracted Amazon ASIN data, it is time to put your data into action strategically. Let us look at some places where you can leverage ASIN code for your business success:
Accurate Monitoring
It is easier to track the product's location and maintain inventory records. With a perfect balance in the inventory, you can fulfill customer demands.
Personalize User Experience
Exploring competitors' products and customer favorites with just an ASIN code is more accessible. This helps to promote your products to potential customers and optimize them for better conversion.
Dynamic Pricing
With bulk structured data, analyzing the market's pricing strategies is effortless. It can offer deals and discounts to your customers at peak hours while making high profits.
Optimize Product Data
You can look for your competitor's product details like descriptions, ratings, reviews, popularity, and pricing to understand the strengths and weaknesses. This approach lets you know the exact customer expectations, and you can easily optimize product data to hit the right spot.
Why choose Web Screen Scraping for Amazon ASIN Data Scraping Services?
Throughout this content, we have explored the Amazon ASIN code, scraping methods, challenges, best practices, and use cases. Following the legal techniques of scraping Amazon ASIN data will bring you data-driven results. It will also let you make informed decisions to beat the competition and update the product information as per customer demands.
But where do we come into play? It would be best to get an expert when choosing the right tools and strategies, structuring extracted data, or following legal measures for data scraping. At Web Screen Scraping, we have over a decade of serving in the data crawling and extraction industry, dealing with various industries. Our experts are prepared to handle any requirement while following legal methods to extract data.