
LinkedIn is a beneficial social network for job hunters and for everyone who wants to expand their contacts and connections. It has millions of people and, therefore, stands as one of the best platforms for looking for job vacancies. However, finding job posts by browsing the internet is a time-consuming process. This guide will help you understand how to collect LinkedIn job postings so you can easily view all the jobs and search for specific ones.
What is LinkedIn Data Scraping?
LinkedIn data scraping is the act of extracting information from LinkedIn profiles, jobs, and other data accessible on the LinkedIn platform through the use of automated tools or scripts. Scraping tools can acquire this information en masse, unlike traditional data mining, where one has to search for specific information such as job titles, company names, or contact information on LinkedIn. This method is commonly employed in creating databases for employment, advertising, or client procurement; it helps evaluate trends or in searching for better candidates.
Nevertheless, data scraping is not allowed on LinkedIn. This is against the platform's terms of service, as it may lead to invasion of privacy and misuse of users' information. The legal consequences of scraping data from LinkedIn include an account suspension or even a lawsuit against the companies or individuals involved. So, we must work with LinkedIn's official tools, such as API or paid services, to obtain the data legally.
What is the Need to Scrape LinkedIn Job Postings?
Using LinkedIn job postings can be beneficial for job seekers and companies. Here's a detailed and easy-to-understand explanation of why it's useful:
Saves Time
On this site, you can spend a lot of time, especially if you are searching for a job and going through the hundreds of job offers. Scraping tools can help by pulling in job postings quickly and in large numbers. A simple click-through method with one page is designed to make the whole process faster and easier to find the jobs of your dreams.
Gathers Critical Job Information
Job seekers who wish to get more details about the job, such as the job title, the company that provides the job, the job location, and perhaps even the job description or salary. This is a gathering job by scraping LinkedIn job postings. This information is then captured and arranged by computers in an auto-case scenario. Consequently, you do not need to waste your time copying and pasting that information separately. Using this collection mechanism, you obtain the information you can easily compare to find the most appropriate option.
Comprehend Job Market Trends
Job market behaviors, however, can be better understood by capturing large amounts of job postings. You can realize, for instance, that some skills are better in demand or that specific job titles are being frequently published if you scrape many job postings. This may be helpful for job seekers who need to determine which skills they should master. Companies can also utilize the information to revise the hiring process to stay in the market.
Competitor Analysis
Scraping job postings from the internet is an insult to any given company. It can be used as a tracking tool against the other companies that are the company's competitors. If a competitor aggressively hires these roles, they could probably be growing or introducing new products. This will give them a significant edge and help them plan their strategies more efficiently.
Improvement in the hiring process
Employers and recruiters can use scraping to track job postings in their industry and build a pool of potential candidates. Scraping then becomes an instrument of connecting recruiters with high-demand jobs, and consequently, they visit the right places to conduct their recruitment activities.
Be Informed About Job Updates
LinkedIn's regularly updated job postings automate the process. Scraping tools are used to stay ahead of the curve and avoid missing out on possible job openings. This is especially useful if you're actively looking for a job and want to apply when a new position becomes available.
However, it's important to remember that LinkedIn has rules against scraping without permission. If done improperly, scraping could lead to your account being suspended or even legal action. To avoid this, using LinkedIn's official tools or getting permission if needed is best.
Challenges of Scraping Job Postings from LinkedIn
Some difficulties arise when scraping data from LinkedIn. Here are some of the main challenges:
Legal and Ethical Issues
LinkedIn's terms of service prohibit unauthorized scraping. If caught, people or companies can have their accounts suspended, arrested, or fined. Unauthorized scraping can also raise ethical problems, especially regarding the privacy of LinkedIn users whose data is being extracted without permission.
Technical Barriers
LinkedIn has implemented measures to combat scraping, including CAPTCHA tests, IP locking, and rate limiting. These barriers can affect scraping tools' reliability and sustainability because they may be locked after sending many requests in a certain amount of time.
Data Accuracy
Scraping tools may not always get data properly because LinkedIn changes often with time or design. Since LinkedIn can change the structure of its website periodically or the format of its job postings, web scraping can sometimes retrieve wrong or limited information.
Data Volume and Management
It is easy to scrape large quantities of information from LinkedIn, creating vast volumes of information that must be addressed. Dealing with this data can be a process, and putting in proper systems to sort, scrub, and structure it is crucial. But, it becomes difficult to manage if the right tools are not in place.
Account Risk
If you use scraping tools with your LinkedIn account, there are some dangers, such as getting banned by LinkedIn's system. If your account is affiliated with such activities, then you will be limited from using the platform for network connections or seeking a job.
Limited Access to Some Data
Some data could not be scraped from LinkedIn; individual profiles are set to private or information behind subscription paywalls (LinkedIn Premium). This restricts the quantity of information accessible for scraping and, therefore, the broader collections of data that can be accrued.
How to Scrape Job Postings from LinkedIn
Install the below-mentioned libraries
pip install requests pip install beautifulsoup4
Determine how LinkedIn job search works.
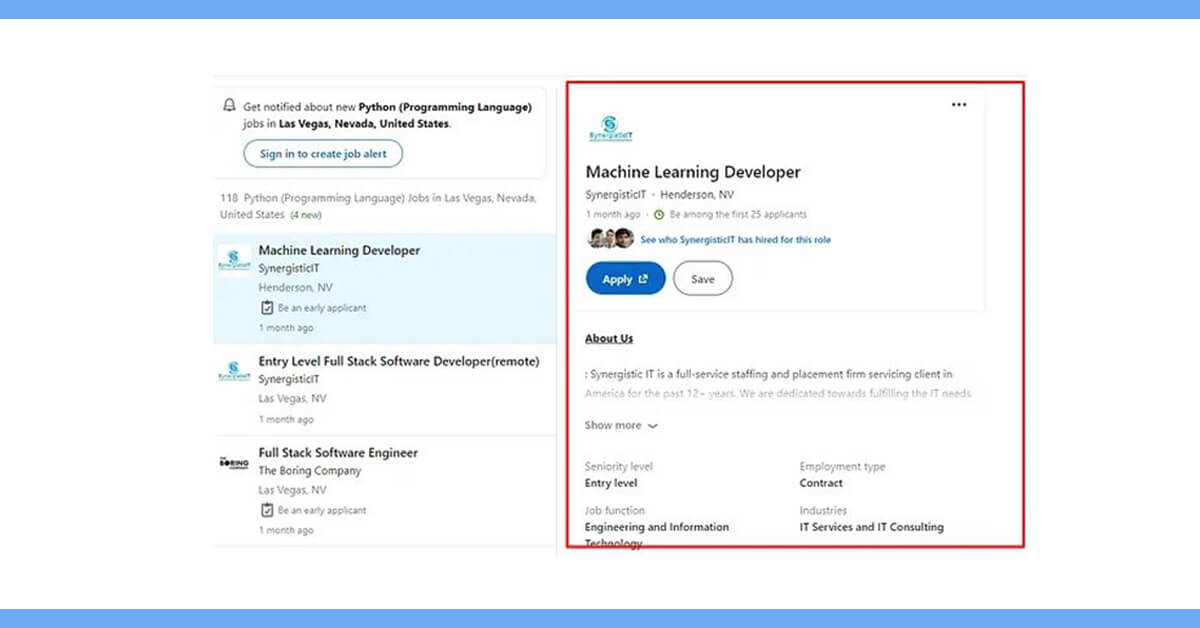
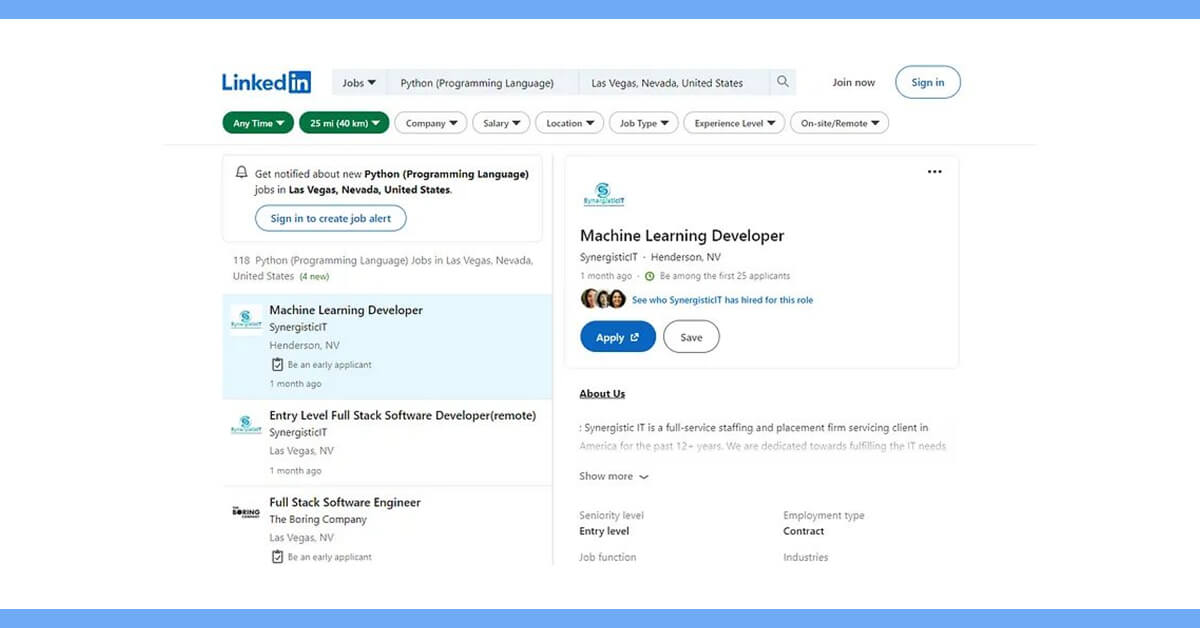
For a Python job in the Las Vegas, visit this page. Let's have a look at the page's URL, which is as follows: https://www.linkedin.com/jobs/search?keywords=Python (Programming Language)&location=Las Vegas, Nevada, United States&geoId=100293800¤tJobId=3415227738&position=1&pageNum=0
Let me explain it to you.
- keywords: Python (Programming Language)
- location: Las Vegas, Nevada, United States
- geoId: 100293800
- currentJobId: 3415227738
- position: 1
- pageNum: 0
There are 118 jobs total on this page, but the pageNum remains unchanged as I navigate to the next page (this page has unlimited scrolling). The challenge then becomes, how can we scrape every job?
A Selenium web driver can be used to fix the problem mentioned above. To extract every page, we can utilize the.execute_script() method to scroll down the page.
The second issue is figuring out how to retrieve data highlighted on the right side of the page. Additional information about each chosen job, such as pay and duration, will be shown in the box.
We can use the Selenium.click() function. Using that logic, you must use a for loop to review each job displayed and click on each one to get information in the corresponding box.
Although this approach is accurate, it takes too much time. Clicking and scrolling will strain our hardware, preventing large-scale scraping.
Discovering the answer into devtool
Let's launch our development tool and reload our target page. Let's examine the contents of our network tab.
As we know, LinkedIn loads the second page by using infinite scrolling. By scrolling down to the second, let's see if anything appears in our network tab.
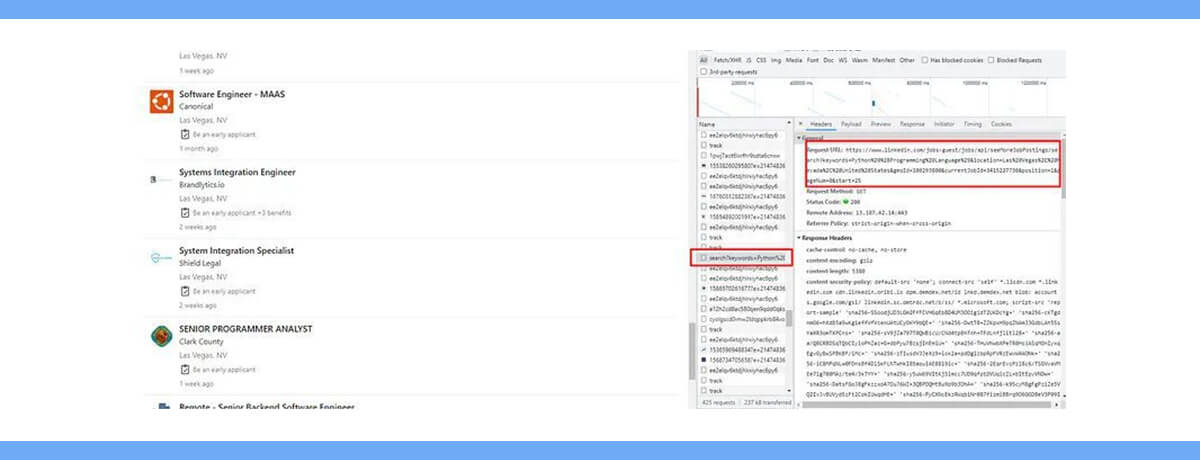
We already know that LinkedIn loads the second page through infinite scrolling. Let's see if anything appears in our network tab by scrolling down to the second.
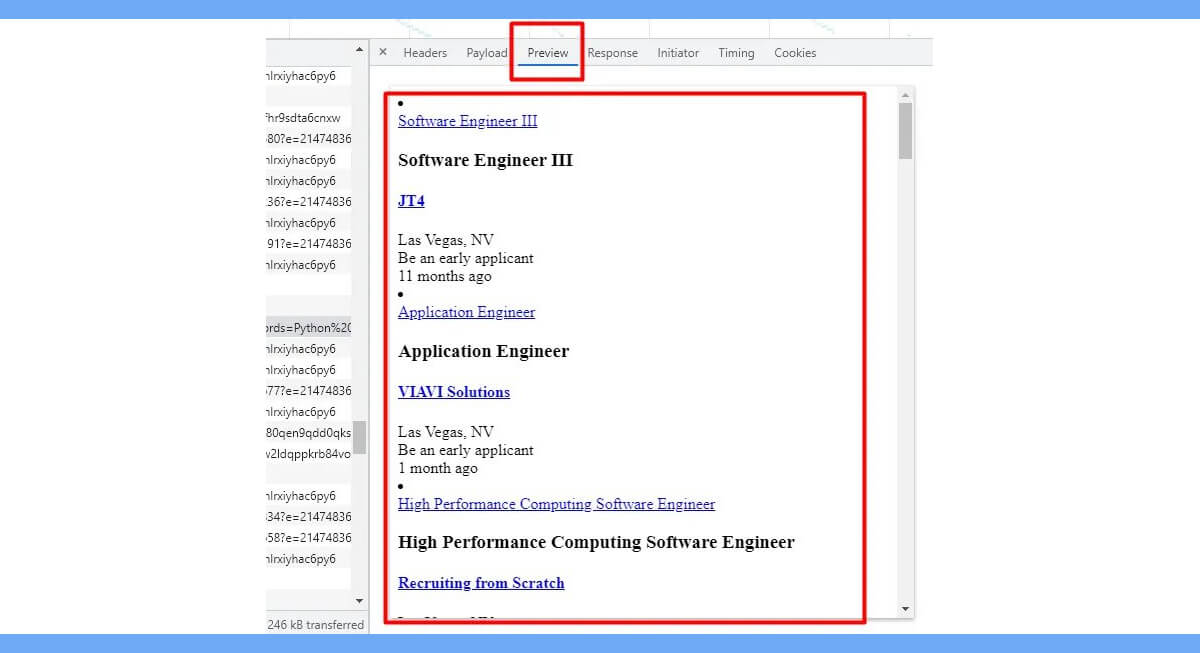
Let's launch our browser and open this URL.
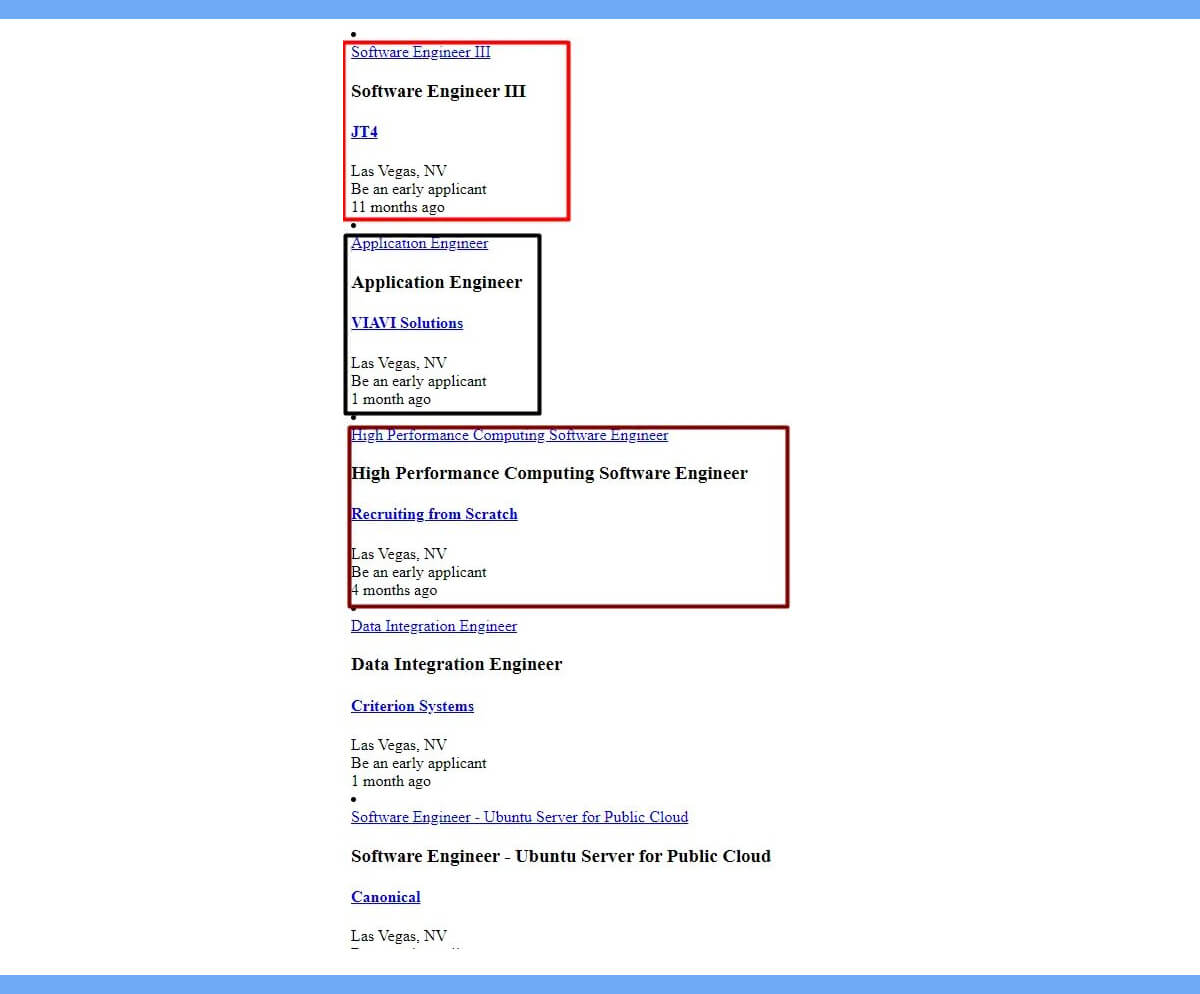
We can now conclude that LinkedIn will send a GET request to the aforementioned URL to load all of the jobs that are posted each time you scroll and the site loads a new page.
To further understand how the URL functions, let's dissect it.
Alright, we now have a way to obtain all of the listed.
https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Python (Programming Language)&location=Las Vegas, Nevada, United States&geoId=100293800¤tJobId=3415227738&position=1&pageNum=0&start=25
- keywords: Python (Programming Language)
- location: Las Vegas, Nevada, United States
- geoId: 100293800
- currentJobId: 3415227738
- position: 1
- pageNum: 0
- start: 25
The start parameter is the only one that varies in every page. The start value will change to 50 when you reach the 3rd page. For each additional page, the initial value will rise by 25. Another thing you'll notice is that the last job will get buried if you increase the value of start by 1.
Indeed, we now understand how to get any of the listed jobs. The information that appears when you click on any job on the right—what about it? How do I get that?
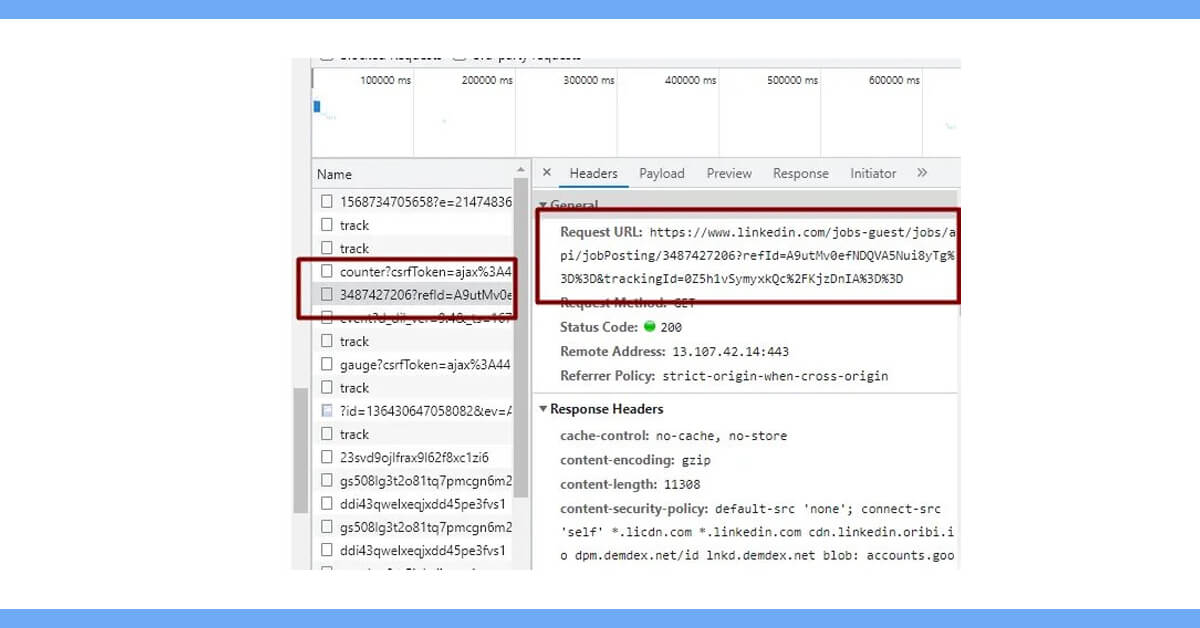
Every time a job is clicked, LinkedIn sends a request- GET to this URL. However, the URL contains an excessive amount of noise. This is how the URL will appear in its most basic form: https://www.linkedin.com/jobs-guest/jobs/api/jobPosting/3415227738 \
The current JobId, which appears in the li tag of every job posted on the platform, is 3415227738.
We now know how to go around Selenium and improve the scalability and dependability of our scraper. Now, we can use the requests library to extract all of this data with a straightforward GET request.
What are we Aiming to scrape?
Selecting the precise information you wish to extract from a website in advance is always preferable. Three items will be scraped for this tutorial.
- Name of the company
- Job position
- Seniority Level

We will scrape all of the jobs using BeautifulSoup's.find_all() method. Next, we will extract each job's jobid. We will then extract job data from this API.
Scraping Jobs IDs from Linkedin
First, let's import every library.
import requests from bs4 import BeautifulSoup
This page lists 117 Python jobs available in Las Vegas.
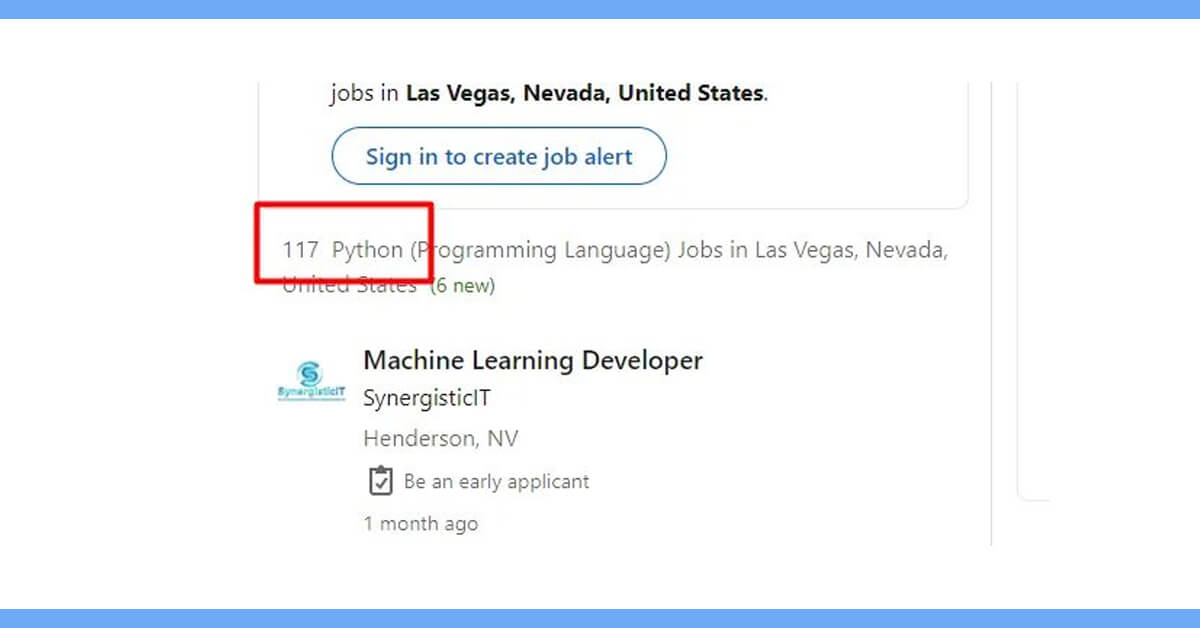
Since each page displays 25 jobs, here explains how our approach will help us scrape every position.
117 divided by 25 We will use the math.ceil() method to the value if it is a float number or whole number.
import requests
from bs4 import BeautifulSoup
import math
target_url='https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Python%20%28Programming%20Language%29&location=Las%20Vegas%2C%20Nevada%2C%20United%20States&geoId=100293800¤tJobId=3415227738&start={}'
number_of_loops=math.ceil(117/25)
Let's look at where job IDs are located in DOM.

Under the div tag, next to the class base-card, is the ID. You need to find the data-entity-urn attribute inside this element in order to get the ID.
We need to use nested for loops to get the Job Ids for every job. The first loop will change the page, while the second loop will go over each job on each page.
target_url='https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Python%20%28Programming%20Language%29&location=Las%20Vegas%2C%20Nevada%2C%20United%20States&geoId=100293800¤tJobId=3415227738&start={}'
for i in range(0,math.ceil(117/25)):
res = requests.get(target_url.format(i))
soup=BeautifulSoup(res.text,'html.parser')
alljobs_on_this_page=soup.find_all("li")
for x in range(0,len(alljobs_on_this_page)):
jobid = alljobs_on_this_page[x].find("div",{"class":"base-card"}).get('data-entity-urn').split(":")[3]
l.append(jobid)
This is a detailed breakdown of the code mentioned above.
We have specified a target URL that contains jobs.
After that, a for loop is run through to the last page.
We then sent a GET request to the page.
We are using BS4 to generate a parse tree constructor.
Because all jobs are contained within li tags, we can use the.find_all() method to find every li tag.
We then started a fresh loop that would keep going until the finished product showed up on any page.
The location of the job ID is being ascertained.
Each and every ID has been added to an array.
All of the ids for every location will eventually be in array l.
Scraping Job Details
Let's locate where the Firm name appears in the DOM.

The value of the alt tag, which is located inside the div tag with class top-card-layout__card, contains the firm name.

The div tag with class top-card-layout__entity-info contains the job title. The text is included within this div element's first a tag.
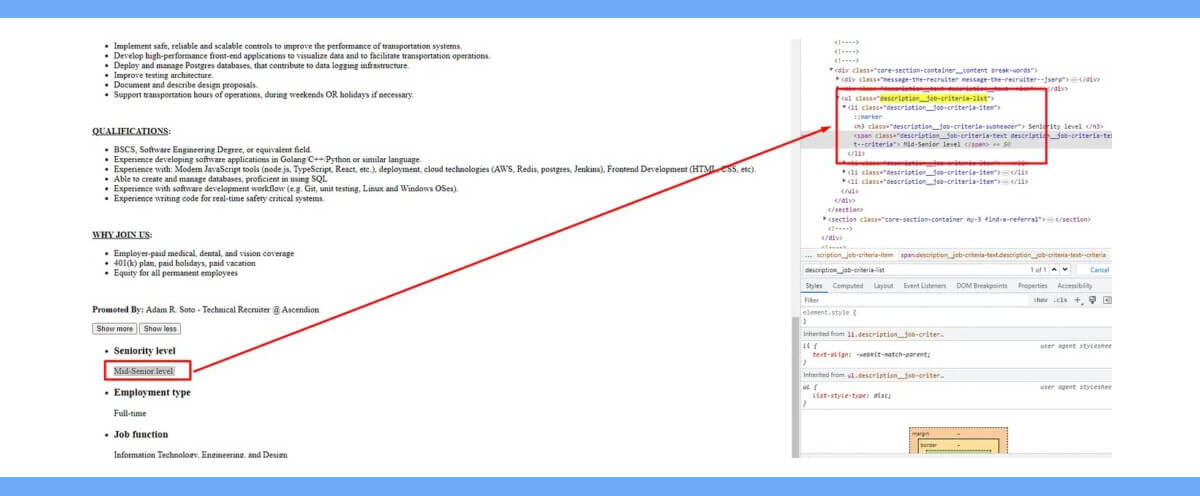
The first li tag of the ul tag with class description__job-criteria-list contains the seniority level.
A GET request will now be sent to the specific URL of the job page. The information we are trying to pull from Linkedin will be available on this page. We will look for these specific items inside BS4 using the DOM element positions listed above.
target_url='https://www.linkedin.com/jobs-guest/jobs/api/jobPosting/{}'
for j in range(0,len(l)):
resp = requests.get(target_url.format(l[j]))
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["company"]=soup.find("div",{"class":"top-card-layout__card"}).find("a").find("img").get('alt')
except:
o["company"]=None
try:
o["job-title"]=soup.find("div",{"class":"top-card-layout__entity-info"}).find("a").text.strip()
except:
o["job-title"]=None
try:
o["level"]=soup.find("ul",{"class":"description__job-criteria-list"}).find("li").text.replace("Seniority level","").strip()
except:
o["level"]=None
k.append(o)
o={}
print(k)
We have established a URL that has the specific Linkedin job URL for each organization.
A for loop will be used to determine how many IDs are in the array l.
We then submitted a GET request to the LinkedIn page.
again produced a BS4 parse tree.
Then, we are using try/except statements to extract all of the data.
Array k now contains object o.
To store data from a different URL, declare the object empty.
The array k is finally printed.
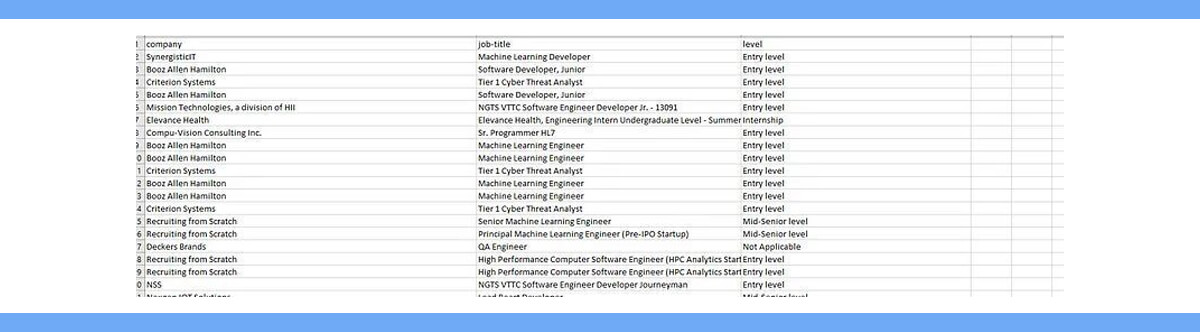
After printing, this is the result.

Saving the data to a CSV file
The pandas library will be used for this process. It only takes two lines of code to save our array to a CSV file.
Steps to install
pip install pandas
Import this library in our main Python file.
import pandas as pd
We will now transform our list to a column and row structure using the DataFrame technique. Next, we will transform a DataFrame to a CSV file using the.to_csv() method.
df = pd.DataFrame(k)
df.to_csv('linkedinjobs.csv', index=False, encoding='utf-8')
You can add these two lines when your list is complete with all the data. Following the completion of the application, a CSV file named linkedinjobs.csv will be placed in your root folder.
Complete Code
import requests
from bs4 import BeautifulSoup
import math
import pandas as pd
l=[]
o={}
k=[]
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"}
target_url='https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Python%20%28Programming%20Language%29&location=Las%20Vegas%2C%20Nevada%2C%20United%20States&geoId=100293800¤tJobId=3415227738&start={}'
for i in range(0,math.ceil(117/25)):
res = requests.get(target_url.format(i))
soup=BeautifulSoup(res.text,'html.parser')
alljobs_on_this_page=soup.find_all("li")
print(len(alljobs_on_this_page))
for x in range(0,len(alljobs_on_this_page)):
jobid = alljobs_on_this_page[x].find("div",{"class":"base-card"}).get('data-entity-urn').split(":")[3]
l.append(jobid)
target_url='https://www.linkedin.com/jobs-guest/jobs/api/jobPosting/{}'
for j in range(0,len(l)):
resp = requests.get(target_url.format(l[j]))
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["company"]=soup.find("div",{"class":"top-card-layout__card"}).find("a").find("img").get('alt')
except:
o["company"]=None
try:
o["job-title"]=soup.find("div",{"class":"top-card-layout__entity-info"}).find("a").text.strip()
except:
o["job-title"]=None
try:
o["level"]=soup.find("ul",{"class":"description__job-criteria-list"}).find("li").text.replace("Seniority level","").strip()
except:
o["level"]=None
k.append(o)
o={}
df = pd.DataFrame(k)
df.to_csv('linkedinjobs.csv', index=False, encoding='utf-8')
print(k)
Conclusion
LinkedIn job listings are immensely valuable for not only job seekers but for recruitment professionals and can dramatically transform the whole employment seeking and selection process. There exist methods for the collection of job information that should be used and an understanding of the benefits of doing so should be gained. Regardless of the programming languages , Python or tools used by ReviewGators is to provide efficient data extraction of the details like job title, company name, location etc.
Once you’re done scraping the data, it can be employed in job search as well as industry analysis. This lets you predict what fields are popular, that is, which skills are sought after, the typical salaries, and employers offering jobs. Having this data in your possession provides you with a competitive advantage in landing jobs, career transitions, or hiring the best candidates. It enables you to defend yourself and make a wise decision in the current ever changing job marketplace.