
The largest travel website in the world, TripAdvisor, is a well-liked resource for discovering lodging, dining, transit options, and tourist attractions. Over 8 million places (hotels, restaurants, and tourist attractions) are listed on TripAdvisor, ranking first in US travel and tourism with over 702 million reviews. To locate the best locations to stay and see when making travel arrangements to a country or city, people frequently turn to TripAdvisor.
Data has significantly impacted every aspect of our daily life. We have a ton of unstructured data that is publicly available online. You can collect unstructured data and transform it into structured information using web scraping.
What does web scraping mean?
Web scraping is a computerized technique for gathering copious data from websites. A database or spreadsheet converts unstructured HTML data into structured data.
We are scraping the TripAdvisor website to parse the hotel costs provided by several sources for the same hotel in a city.
A travel website called TripAdvisor helps its members with everything from planning to reserving to taking a vacation.
The tools listed below are what we're using to finish this web scraping job.
Due to the abundance of tools designed expressly for online scraping, Python is one of the most often used languages for the task.
Another excellent Python tool for web scraping is Beautiful Soup; it generates a parse tree that extracts data from HTML on a website.
To do browser manipulation for web scraping, the Selenium Web Driver is a tool for testing an application's front end.
Pandas is a tool for reading and modifying data.
Steps to Extract TripAdvisor Hotel Details Using Python
- Installing and importing the necessary packages
- Create the object for the Selenium web driver.
- You can access the hotel's page by giving the web driver object the necessary inputs.
- From the loaded website source, create a Beautiful Soup object, and then parse the information about the hotel from the Beautiful Soup object.
- Use Pandas to write the parsed data to a CSV file.
- Open the CSV file and use Pandas to view the data.
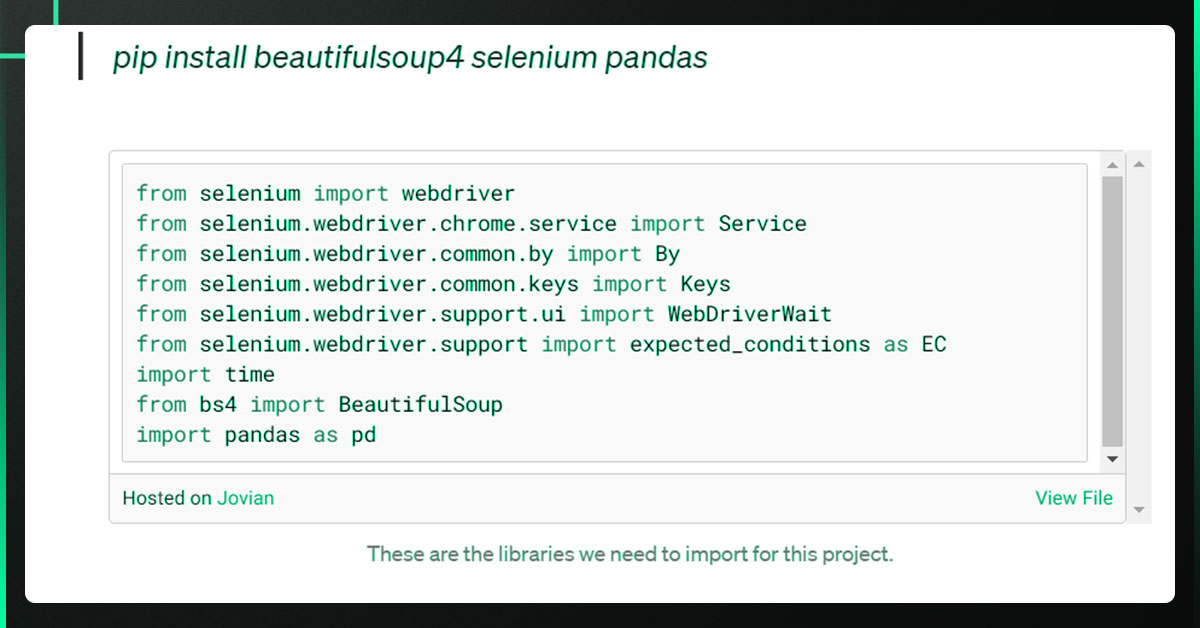
Installing and Importing Necessary Packages
PIP is Python's default package management system. To install the necessary packages, use the command below.
Create the Object for the Selenium Web Driver
By giving a path to the chrome driver and the necessary additional settings, we must establish a web driver instance of the relevant browser type to simulate the web browser.
def get_driver_object():
"""
Creates and returns the selenium webdriver object
Returns:
Chromedriver object: This driver object can be used to simulate the webbrowser
"""
# Creating the service object to pass the executable chromedriver path to webdriver
service_object = Service(executable_path=CHROME_DRIVER_PATH)
# Creating the ChromeOptions object to pass the additional arguments to webdriver
options = webdriver.ChromeOptions()
# Adding the arguments to ChromeOptions object
options.headless = True #To run the chrome without GUI
options.add_argument("start-maximized") #To start the window maximised
options.add_argument("--disable-extensions") #To disable all the browser extensions
options.add_argument("--log-level=3") #To to capture the logs from level 3 or above
options.add_experimental_option(
"prefs", {"profile.managed_default_content_settings.images": 2}
) #To disable the images that are loaded when the website is opened
# Creating the Webdriver object of type Chrome by passing service and options arguments
driver_object = webdriver.Chrome(service=service_object,options=options)
return driver_object
We must open the website by providing the URL to the get() method of the driver instance.
def get_website_driver(driver=get_driver_object(),url=SCRAPING_URL):
"""it will get the chromedriver object and opens the given URL
Args:
driver (Chromedriver): _description_. Defaults to get_driver_object().
url (str, optional): URL of the website. Defaults to SCRAPING_URL.
Returns:
Chromedriver: The driver where the given url is opened.
"""
# Opening the URL with the created driver object
print("The webdriver is created")
driver.get(url)
print(f"The URL '{url}' is opened")
return driver
You can access the hotel's page by giving the web driver object the necessary inputs.
- You can use several utility functions to crawl the hostel website from the home page.
- A helper function called search hotels() calls another helper method to crawl to the hotel's page.
def search_hotels(driver):
"""Opens the Hotels page from which the data can be parsed.
Args:
driver (Chromedriver): The driver where the url is opened.
"""
#Opening the Hotels tab with the given city and waiting for it to load
open_hotels_tab(driver)
time.sleep(10)
#Selecting the Check In and Check Out Dates
select_check_in_out_dates(driver)
#Updating the details
update_button(driver)
time.sleep(10)
We must instruct the specific HTML element to take activities on the website. In the search bar below, enter the city name to identify this Tag specifically using the input Tag and placeholder attribute.
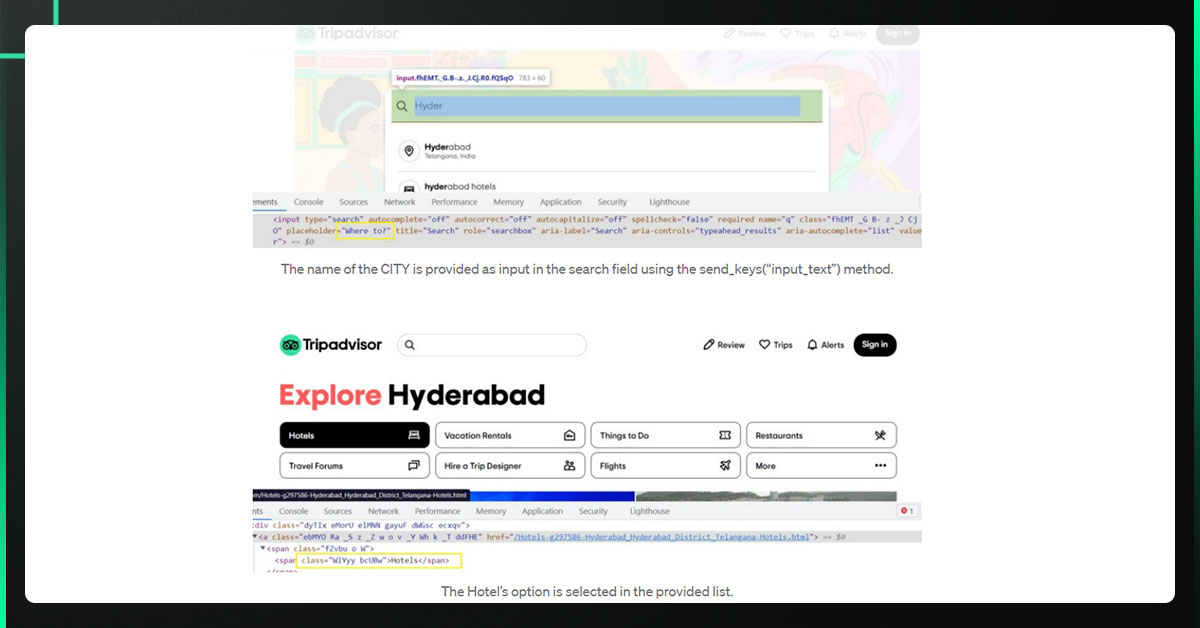
Using the driver object, we can perform similar operations on tabs, check-ins, and check-outs.
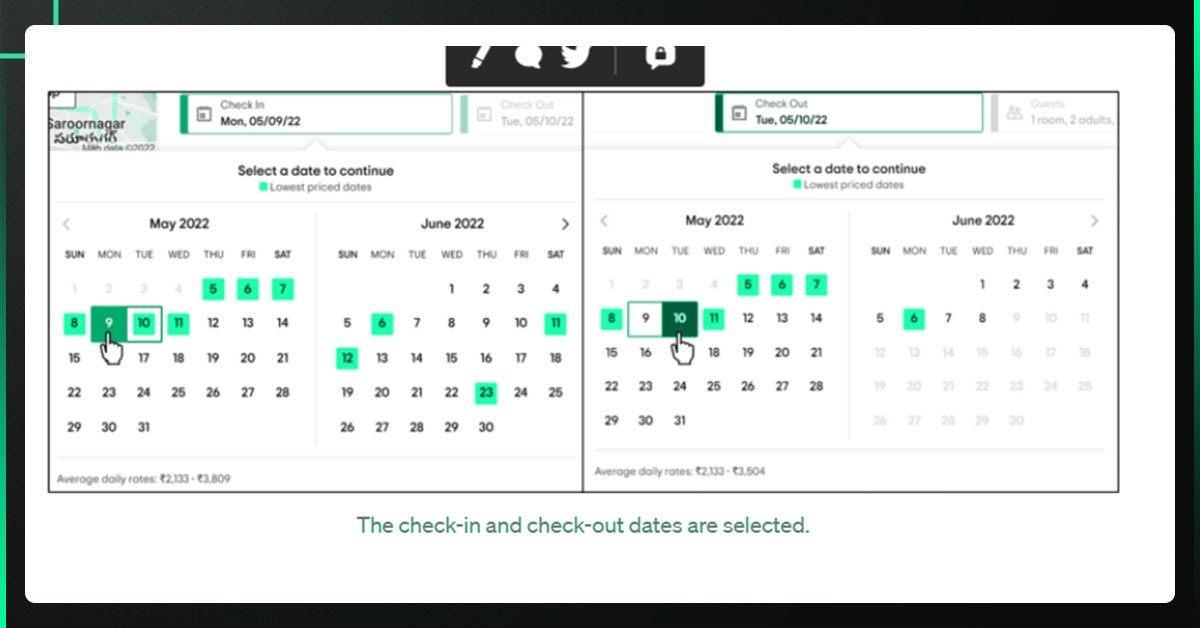
While supplying the inputs, the web page loads dynamically; therefore, we must wait until it has finished loading before giving the driver additional instructions.
In the Jupyter notebook hosted on Jovian, you can find the additional utility functions open hotels tab(), select check-in out dates(), select check-in(), select check out(), and update button().
You can parse the data about the hotel using the Beautiful Soup object created from the loaded page source.
Want to extract hotel details on TripAdvisor?
Request a Quote!
The Beautiful Soup Class receives the driver when creating a Beautiful Soup object. Page source.
We have chosen the hotel div element, which has all the hotel details, from among the HTML code that makes up the Soup object, representing the loaded page.
def parse_hotels(driver):
""" To parse th web page using the BeautifulSoup
Args:
driver (Chromedriver): The driver instance where the hotel details are loaded
"""
# Getting the HTML page source
html_source = driver.page_source
# Creating the BeautifulSoup object with the html source
soup = BeautifulSoup(html_source,"html.parser")
# Finding all the Hotel Div's in the BeautifulSoup object
hotel_tags = soup.find_all("div",{"data-prwidget-name":"meta_hsx_responsive_listing"})
# Parsing the hotel details
for hotel in hotel_tags:
# condition to check if the hotel is sponsered, ignore this hotel if it is sponsered
sponsered = False if hotel.find("span",class_="ui_merchandising_pill") is None else True
if not sponsered:
parse_hotel_details(hotel)
print("The Hotels details in the current page are parsed")
The helper method parses_hotel_details(), takes the hotel div element, and parses the hotel details indicated below.
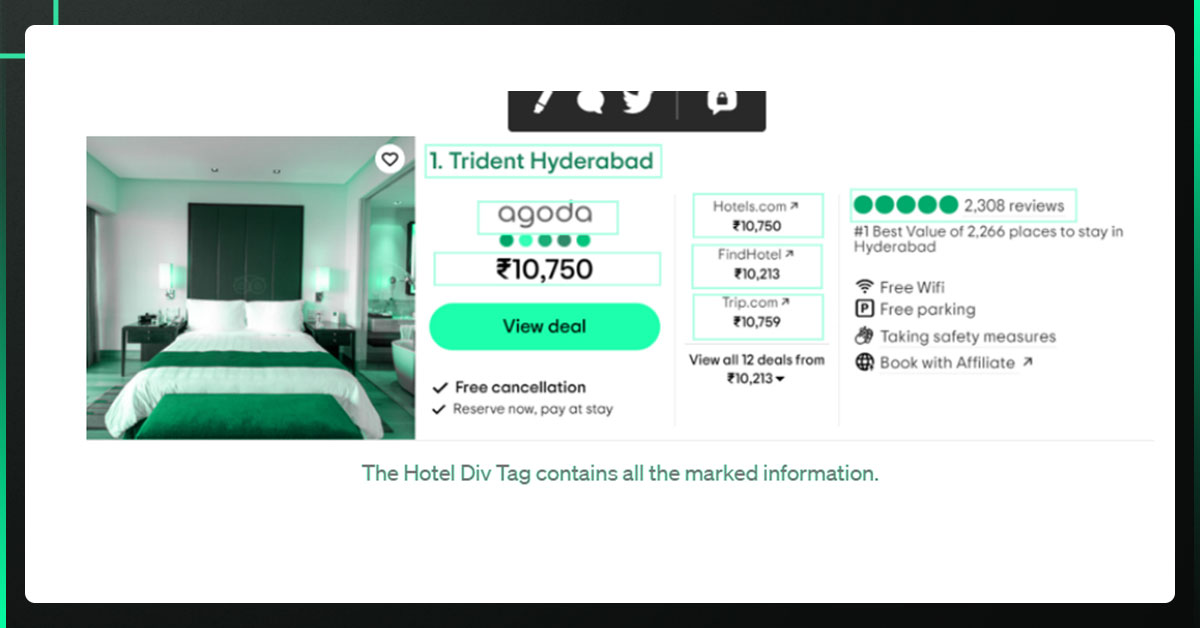
def parse_hotel_details(hotel):
"""Parse the hotel details from the given hotel div element
Args:
hotel (Beautifulsoup object): The hotel div element which contains hotel details
"""
#declaring the global variables
global HOTELS_LIST
#Parsing the best offer Hotel Details
best_offer_deals = parse_best_offer(hotel)
#Parsing the other offers Hotel Details
hotel_details = parse_other_offers(hotel,best_offer_deals)
# Apending the data to the hotels list
HOTELS_LIST.append(hotel_details)
To parse the hotel information, we have written two additional helper functions, parse_best_offer() and parse_other_offers().
Use Pandas to write the parsed data to a CSV file.
Create a Pandas DataFrame object with the list of hotel details and use the pandas.DataFrame.to CSV method to save the information to a CSV file ().
def write_to_csv():
"""To Write the hotels data in to a CSV file using pandas
"""
#declaring the global variables
global HOTELS_LIST,HOTELS_DF
# Creating the pandas DataFrame object
HOTELS_DF = pd.DataFrame(HOTELS_LIST,index=None)
# Viewing the DataFrame
print(f"The number of columns parsed is {HOTELS_DF.shape[1]}")
print(f"The number of rows parsed is {HOTELS_DF.shape[0]}")
# Conveting the DataFrame to CSV file
HOTELS_DF.to_csv("hotels_list.csv",index=False)
print("The CSV file is created at hotels_list.csv")
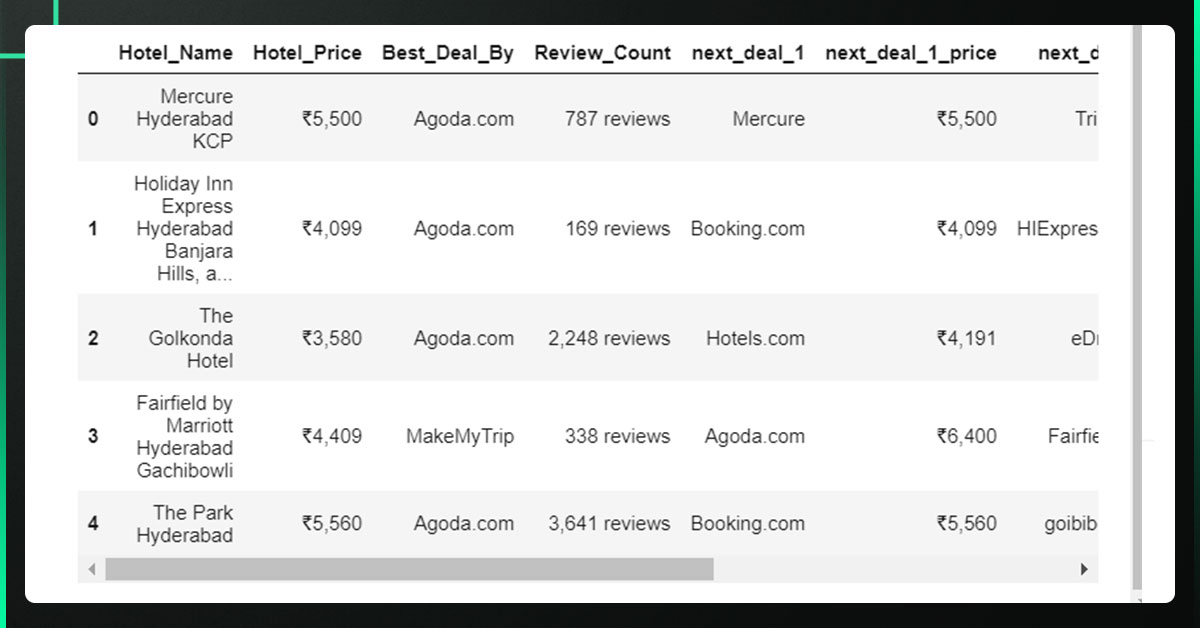
Open the CSV file and use Pandas to view the data.
The data can be loaded from a CSV file using the pandas read csv() method.
hotels_csv_file = pd.read_csv("hotels_list.csv")
hotels_csv_file.head()
Conclusion
- Using the Selenium web driver, we navigated to the hotel listings on the TripAdvisor website. It can simulate human behavior.
- Anyone using Beautiful Soup to parse the information on the loaded page allowed us to obtain the necessary hotel information from the HTML page source.
- By turning our data into a DataFrame object, we have utilized pandas to save the data into a CSV file.
- With a few adjustments to the functions above, we can apply the same technique to gather additional information on the website. The information gathered can then be used for further research.
If you are looking to scrape TripAdvisor Data, contact Web Screen Scraping today!
Request for a quote!